An Open Source optical character recognition (OCR) program, implemented as a filter. #OCR program #Image recognition #Character recognition #OCR #Character #Recognition
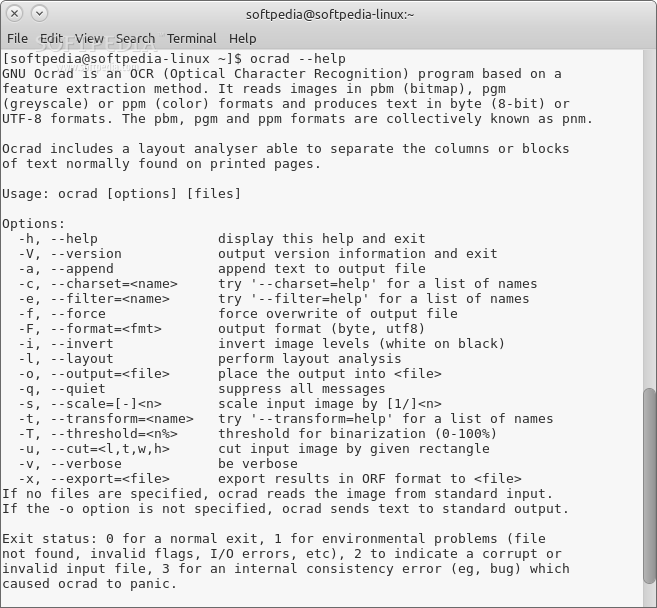
GNU Ocrad is an open source command-line software designed to act as an OCR (Optical Character Recognition) daemon for Linux-based operating systems. It is implemented as a filter and it’s based on a feature extraction method, but it can also be used as a standalone program or as a backend to other OCR applications.
Key features include the ability to read images in PBM (bitmap), PPM (color) and PGM (grayscale) formats, which are collectively known as PNM. It produces text in UTF-8 or byte (8-bit) formats and includes a layout analyzer, which is capable of separating the blocks or columns of text that are normally found on printed pages.
Command-line options include the ability to append text to output file, choose specific filters and characters, force overwrite of output file, inver image levers (black and white), perform layout analysis, place the output into a specific file, suppress all messages, scale the input image, threshold for binarization, cut the input image by a given rectangle and export the results to the ORF file format.
As mentioned in the section below, the application is distributed as a universal sources archive for all GNU/Linux operating systems. To install it and use it, download the tar.lz file, extract it into a folder of your choice, open a terminal emulator and navigate to the extracted folder.
To configure and compile the application, execute the “./configure && make” command (without quotes). To install it, run the “make install” command (without quotes) as root. After installation, execute the “ocrad --help” command (without quotes) to view its help screen.
The program is written entirely in the C++ programming language and runs directly from a command-line environment (e.g. an X11 terminal emulator). It is available for download as a single archive that includes the source code, which must be compiled prior to installation. Supported architectures include 32-bit (x86) and 64-bit (x86_64).
GNU Ocrad 0.24
add to watchlist add to download basket send us an update REPORT- runs on:
- Linux
- main category:
- Multimedia
- developer:
- visit homepage
calibre 7.9.0

7-Zip 23.01 / 24.04 Beta

Bitdefender Antivirus Free 27.0.35.146

Windows Sandbox Launcher 1.0.0

ShareX 16.0.1

Zoom Client 6.0.3.37634

Microsoft Teams 24060.3102.2733.5911 Home / 1.7.00.7956 Work

IrfanView 4.67

4k Video Downloader 1.5.3.0080 Plus / 4.30.0.5655

Context Menu Manager 3.3.3.1

- IrfanView
- 4k Video Downloader
- Context Menu Manager
- calibre
- 7-Zip
- Bitdefender Antivirus Free
- Windows Sandbox Launcher
- ShareX
- Zoom Client
- Microsoft Teams