An Open Source and high-performace search server based on the Apache Lucene library. #Search server #Lucene server #Apache server #Apache #Solr #Lucene
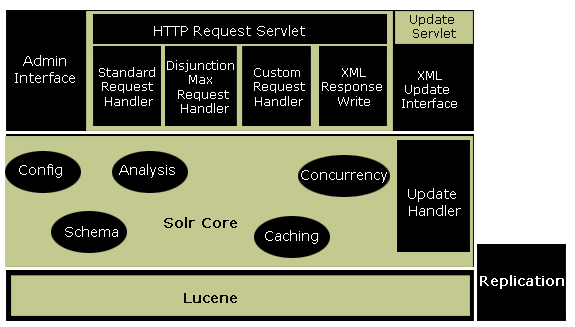
Apache Solr is an open source, free, platform-independent and high-performance search server based on the Apache Lucene project, using XML/HTTP and JSON APIs. The project is currently under incubation at the Apache Software Foundation.
Key features include hit highlighting, faceted search, caching, replication, a web-based administration interface, advanced full-text search capabilities, it is optimized for high volume web traffic, as well as standards based open interfaces, such as HTTP, XML, and JSON.
It comes with comprehensive HTML administration interfaces, server statistics, auto index replication, auto recovery and failover, near real-time indexing, adaptable and flexible with XML configuration, and an extensible plugin architecture.
The project is schemaless, allowing user to quickly get started with Apache Solr. Both schema and schemaless modes are supported at this time, but the latter will lead to a strong production environment.
Various types are supported by Solr, including Field Types, which will help you to mix and match Lucene analyzers without writing any piece of code. The project supports dynamic fields that can be enabled on-the-fly.
Among other interesting features, we can mention the copy field functionality that allows users to easily analyze the same content using different methods, support for explicit types to eliminate the need for guessing types of fields, custom configurations based on external files, as well as numerous additional text analysis components.
Taking a look under the hood of Apache Solr, we can notice that the application has been written entirely in the Java programming language and supports 32-bit and 64-bit distributions of Linux, as well as the Microsoft Windows and Mac OS X operating systems.
For your convenience, it is distributed as both binary and source archives, so you can easily get started with Apache Solr in as minimal time as possible and without too much hassle.
What's new in Apache Solr 7.2.1:
- Overseer can never process some last messages.
- Rename core in solr standalone mode is not persisted.
- QueryComponent's rq parameter parsing no longer considers the defType parameter.
- Fix NPE in SolrQueryParser when the query terms inside a filter clause reduce to nothing.
Apache Solr 7.2.1
add to watchlist add to download basket send us an update REPORT- runs on:
- Linux
- main category:
- Internet
- developer:
- visit homepage
IrfanView 4.67

Microsoft Teams 24060.3102.2733.5911 Home / 1.7.00.7956 Work

7-Zip 23.01 / 24.04 Beta

Context Menu Manager 3.3.3.1

Windows Sandbox Launcher 1.0.0

4k Video Downloader 1.5.3.0080 Plus / 4.30.0.5655

ShareX 16.0.1

Bitdefender Antivirus Free 27.0.35.146

calibre 7.9.0

Zoom Client 6.0.3.37634

- Bitdefender Antivirus Free
- calibre
- Zoom Client
- IrfanView
- Microsoft Teams
- 7-Zip
- Context Menu Manager
- Windows Sandbox Launcher
- 4k Video Downloader
- ShareX