Easily OCR documents in KDE4. #OCR documents #KDE servicemenu #Tesseract #OCR #Documents #Servicemenu
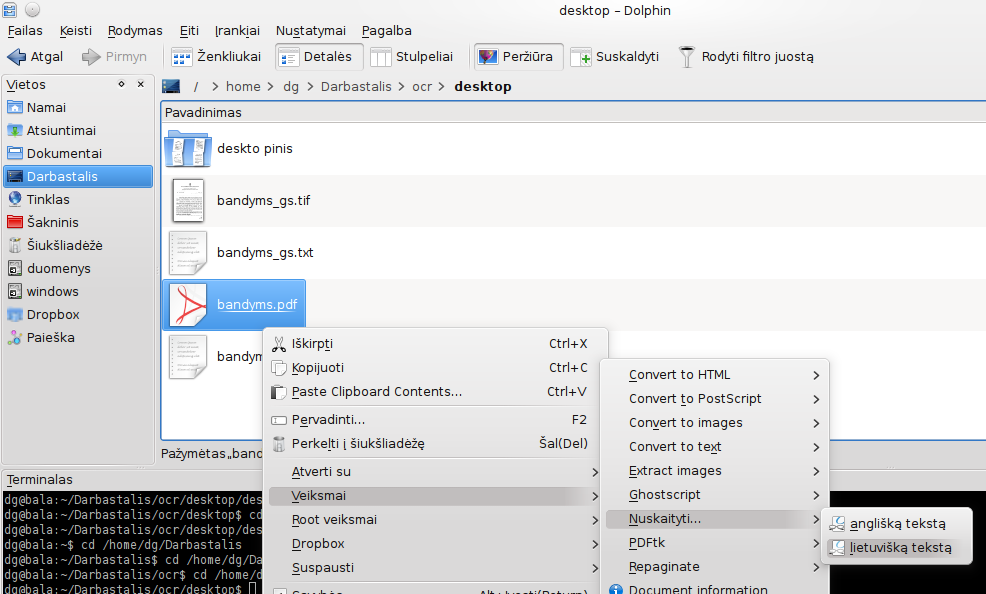
OCR using Tesseract is a servicemenu for Dolphin and Konqueror, compatible with KDE4, that will give you a possibility to OCR documents conveniently in your file manager window.
This is a very simple program. It OCR\'s a document and puts it into a file that has the same name as the OCRed image file but with a txt extension.
For the menu to be visible and have basic functionality (OCR tif files) you have to have tesseract-ocr installed and in your path, as well as the desired language packages. (The menu is tested against tesseract-ocr v. 2.03 and 2.04).
To be able to OCR png and jpeg images you have to have imagemagick installed. To be able to OCR pdf file you have to have ghostscript installed. INSTALLATION: see file readme.txt in the archive.
– The menu cannot handle filenames with spaces (though it tolerates directory names with spaces). No warning is given.
– If the working directory contains a file with a name of the file to be OCRed, that has an extension "tif" or "txt", it will be overwritten or deleted (e.g., if the file to be OCRed is named foobar.tif, foobar.txt will be overwritten; in case of foobar.tiff or foobar.png or foobar.jpg, foobar.tif will be deleted and foobar.txt – overwritten. No warning is given.
– Uppercase extensions (like JPG or PNG) are not supported, and produce a warning that the script does not handle these types of files. Also the long jpg extension "jpeg" is not supported...
I am afraid I will not be spending more time on this menu to solve these problems by myself (I have already surpassed myself in bash when doing this script already), but I will gladly incorporate the patches anyone sends me or posts here.
System requirements
What's new in OCR using Tesseract 0.2.0:
- attempted to make it knewstuff3 compatible – must be installible through the Dolphin services.
- siplified operation – a dialog asks to choose language, while there is only one service menu entry now.
- fixed progress bar error.
- it seems that the problem with directory names with spaces is gone.
OCR using Tesseract 0.2.0
add to watchlist add to download basket send us an update REPORT- runs on:
- Linux
- main category:
- Desktop Environment
- developer:
- visit homepage
ShareX 16.0.1

Zoom Client 6.0.0.37205

4k Video Downloader 1.5.3.0080 Plus / 4.30.0.5655

paint.net 5.0.13 (5.13.8830.42291)

calibre 7.8.0

7-Zip 23.01 / 24.04 Beta

Microsoft Teams 24060.3102.2733.5911 Home / 1.7.00.7956 Work

Bitdefender Antivirus Free 27.0.35.146

IrfanView 4.67

Windows Sandbox Launcher 1.0.0

- Bitdefender Antivirus Free
- IrfanView
- Windows Sandbox Launcher
- ShareX
- Zoom Client
- 4k Video Downloader
- paint.net
- calibre
- 7-Zip
- Microsoft Teams